

🌱 WealthTrax — Phase 1 Walking Skeleton
A behind-the-scenes look at what I’ve been building lately.
Over the past few months I've been quietly working on a personal project called WealthTrax, a lightweight portfolio analyzer designed for anyone juggling multiple investment or savings accounts, especially couples who need to combine and understand their holdings in one place. I started with one clear goal: build a walking skeleton. In other words, create the thinnest possible slice of the system that runs end-to-end in production before adding any real features or polish.
The Walking Skeleton Approach
Getting a fully deployed slice running this early was a strategic choice. With the entire path from UI → GraphQL → Lambda, complete with structured logs and X-Ray tracing, every future feature becomes dramatically easier to design, implement, and evolve. By keeping the components small, modular, and test-driven, the system can adapt naturally as requirements shift or new ideas surface. There's no guessing about infrastructure, no surprises at deployment time, and no ambiguity about how components will integrate. This foundation means development from here on out is fast, incremental, and low-friction.
AI-Native Development
What made this project especially fun is that it also became a practical experiment in AI-native software development. WealthTrax was built almost entirely through a spec-driven workflow powered by ChatGPT and Cursor; writing tests, shaping designs, iterating on architecture, and generating most of the implementation in tight cycles. It felt like working with a high-bandwidth engineering partner: one that can explore alternatives, generate code, refactor, and reason about systems at a pace that fundamentally changes what "individual productivity" looks like. The walking skeleton wasn't just the outcome, it was a demonstration of how modern AI tools can reshape the day-to-day experience of building software.
Architecture
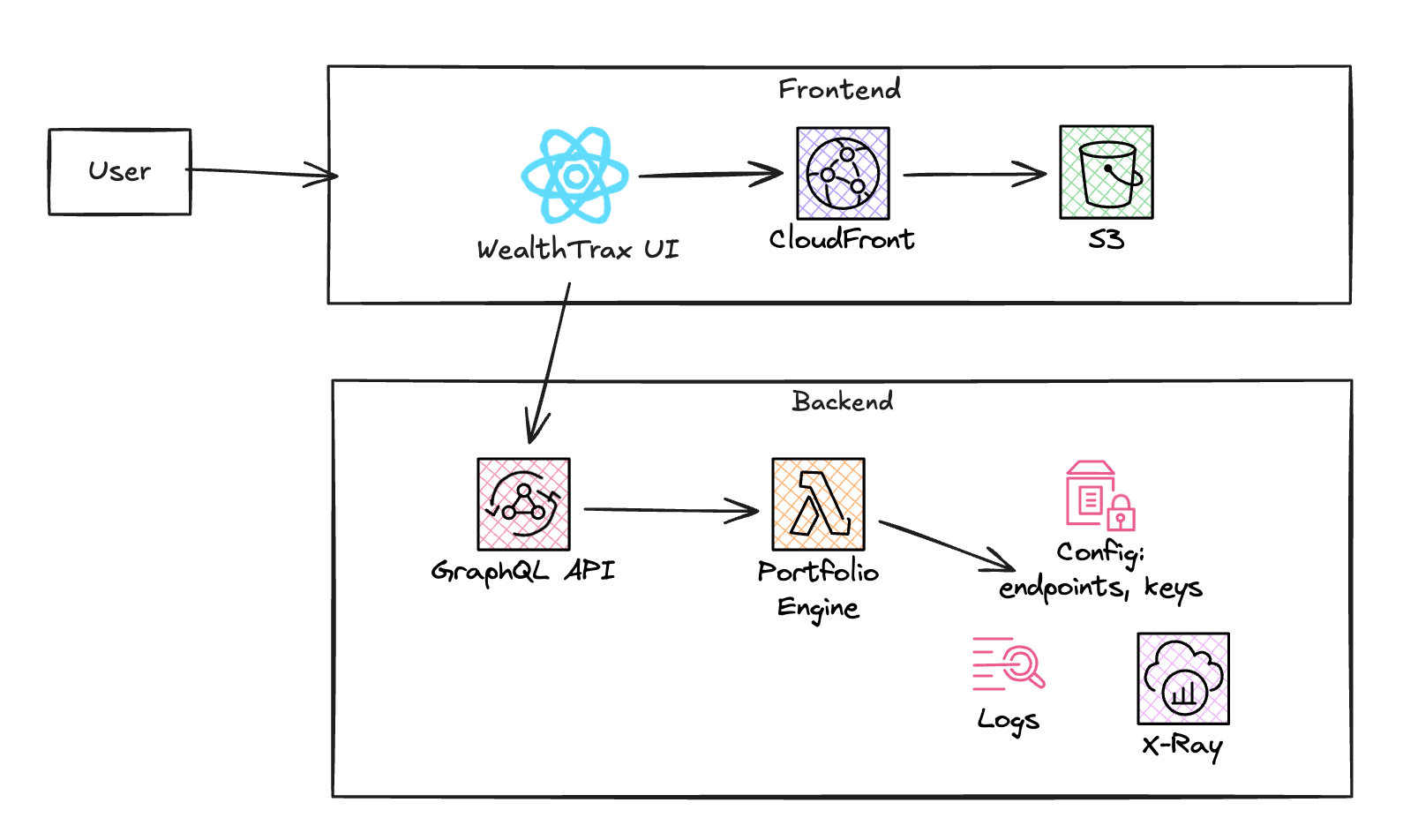
On the backend, the portfolio engine is built with Python and AWS Lambda, using TDD to implement CSV parsing, position aggregation, and category classification. The API is a single AppSync GraphQL mutation, strongly typed and easy to evolve. On the frontend, a Vite + React app calls the API and displays holdings, cash balances, and portfolio percentages. It's intentionally minimal: paste CSV → get insight.
Automation Pipelines
Another major milestone was setting up the automation pipelines. Both the backend and frontend have their own independent GitHub Actions workflows: each one deploys to a stage environment, runs its respective test suite (Behave for the backend, Playwright for the frontend), and then automatically promotes the release to production once stage passes. After deployment, each pipeline runs a set of smoke tests against prod to validate the deploy. All deployments use GitHub's OIDC integration with AWS, so there are no long-lived credentials anywhere in the process. It's clean, secure, and fully automated end-to-end.
What's Next
Phase 1 is now complete, and the skeleton is alive: deployed, observable, and ready to grow. Next up will be adding real-time pricing, stronger monitoring, a file upload option, and eventually more insights around allocation and trends. But starting with a walking skeleton gave me something far more valuable... a stable, deployable foundation and a working rhythm that reflects how I believe software should be built: thin, tested, and continuously deployed.
If you’re curious about the architecture or want a peek at the next phases, let me know. I’m aiming to have an early version available to try out in Q1 of 2026.
- v1.0.0 - Jan 5, 2026